 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstractions for Hierarchical Planning in Program-Synthesis Agents
Jan 31, 2026Humans learn abstractions and use them to plan efficiently to quickly generalize across tasks -- an ability that remains challenging for state-of-the-art large language model (LLM) agents and deep reinforcement learning (RL) systems. Inspired by the cognitive science of how people form abstractions and intuitive theories of their world knowledge, Theory-Based RL (TBRL) systems, such as TheoryCoder, exhibit strong generalization through effective use of abstractions. However, they heavily rely on human-provided abstractions and sidestep the abstraction-learning problem. We introduce TheoryCoder-2, a new TBRL agent that leverages LLMs' in-context learning ability to actively learn reusable abstractions rather than relying on hand-specified ones, by synthesizing abstractions from experience and integrating them into a hierarchical planning process. We conduct experiments on diverse environments, including BabyAI, Minihack and VGDL games like Sokoban. We find that TheoryCoder-2 is significantly more sample-efficient than baseline LLM agents augmented with classical planning domain construction, reasoning-based planning, and prior program-synthesis agents such as WorldCoder. TheoryCoder-2 is able to solve complex tasks that the baselines fail, while only requiring minimal human prompts, unlike prior TBRL systems.
Synthesizing world models for bilevel planning
Mar 26, 2025Modern reinforcement learning (RL) systems have demonstrated remarkable capabilities in complex environments, such as video games. However, they still fall short of achieving human-like sample efficiency and adaptability when learning new domains. Theory-based reinforcement learning (TBRL) is an algorithmic framework specifically designed to address this gap. Modeled on cognitive theories, TBRL leverages structured, causal world models - "theories" - as forward simulators for use in planning, generalization and exploration. Although current TBRL systems provide compelling explanations of how humans learn to play video games, they face several technical limitations: their theory languages are restrictive, and their planning algorithms are not scalable. To address these challenges, we introduce TheoryCoder, an instantiation of TBRL that exploits hierarchical representations of theories and efficient program synthesis methods for more powerful learning and planning. TheoryCoder equips agents with general-purpose abstractions (e.g., "move to"), which are then grounded in a particular environment by learning a low-level transition model (a Python program synthesized from observations by a large language model). A bilevel planning algorithm can exploit this hierarchical structure to solve large domains. We demonstrate that this approach can be successfully applied to diverse and challenging grid-world games, where approaches based on directly synthesizing a policy perform poorly. Ablation studies demonstrate the benefits of using hierarchical abstractions.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
NucMM Dataset: 3D Neuronal Nuclei Instance Segmentation at Sub-Cubic Millimeter Scale
Jul 13, 2021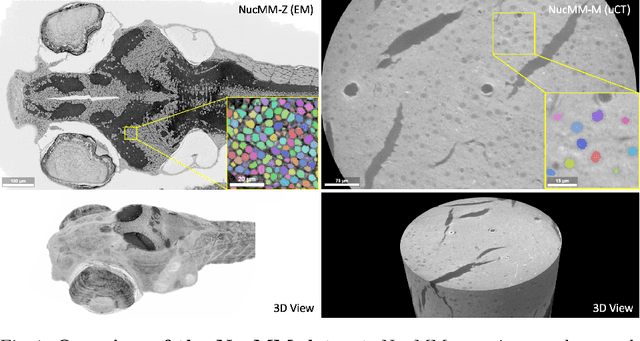

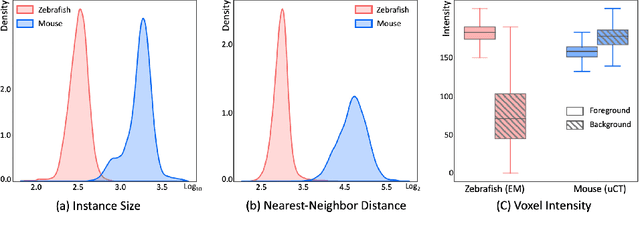
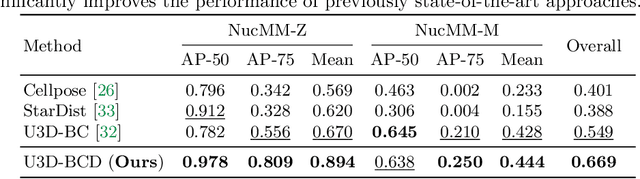
Segmenting 3D cell nuclei from microscopy image volumes is critical for biological and clinical analysis, enabling the study of cellular expression patterns and cell lineages. However, current datasets for neuronal nuclei usually contain volumes smaller than $10^{\text{-}3}\ mm^3$ with fewer than 500 instances per volume, unable to reveal the complexity in large brain regions and restrict the investigation of neuronal structures. In this paper, we have pushed the task forward to the sub-cubic millimeter scale and curated the NucMM dataset with two fully annotated volumes: one $0.1\ mm^3$ electron microscopy (EM) volume containing nearly the entire zebrafish brain with around 170,000 nuclei; and one $0.25\ mm^3$ micro-CT (uCT) volume containing part of a mouse visual cortex with about 7,000 nuclei. With two imaging modalities and significantly increased volume size and instance numbers, we discover a great diversity of neuronal nuclei in appearance and density, introducing new challenges to the field. We also perform a statistical analysis to illustrate those challenges quantitatively. To tackle the challenges, we propose a novel hybrid-representation learning model that combines the merits of foreground mask, contour map, and signed distance transform to produce high-quality 3D masks. The benchmark comparisons on the NucMM dataset show that our proposed method significantly outperforms state-of-the-art nuclei segmentation approaches. Code and data are available at https://connectomics-bazaar.github.io/proj/nucMM/index.html.